
ECS Fargateの高負荷時の対策について記載します。
高負荷時は、基本的には以下の対応となりますが、基本に通りに進める時間的余裕がないことが多いと思います。
- 高負荷の原因となっている処理を特定する
- プログラムを修正して、原因を取り除く
- 対象機能の負荷試験を行う
- 負荷試験にて適切なコンテナタスク数や性能を決める
本記事では、上記を実施する時間的余裕がない場合に、応急処置として、インフラ強化で対応できることを記載していきます。
高負荷状態を放置するとコンテナが落ちて、処理中のデータが失われてしまうこともあるので、緊急時はインフラ強化で対策しておきましょ!
メモリ使用率が高いケース
上記のケースで、どのように対応すれば良いか記載していきます。
以下の3つ対応を適切に使って対応していきます。
スケールアウト
スケールアップ
新しいデプロイの強制→新しいコンテナを起動し、稼働中のコンテナを停止する
まず、上記の3つの高負荷時の対策について、具体的にどんな対策となるか、対策の中身を記載していきます。
高負荷時の対策
高負荷時の対策について、具体的には以下のような対策となります。
スケールアウト:タスク数を増やす
スケールアップ:1タスクのCPUやメモリを大きくする
新しいデプロイの強制:タスクを全て入れ替える(新しいコンテナを起動し、稼働中のコンテナを停止する)
次に、どんな時にどの対策を行えば良いか考えていきます。
CPU使用率が高いケース
CPU使用率が高い場合は以下の対応が基本となります。
アクセス数が増えて高負荷になっている場合:スケールアウト
重い処理が多くて捌き切れない:スケールアップ
アクセス数が増えて高負荷になっている場合、タスク数を増やすことで、多くのアクセスを捌けるようになるため、スケールアウトすれば良いという考えです。
重い処理が多くて捌き切れない場合、タスク数を増やしても、重い処理が1つのタスクに集中してしまうと捌けなくなってしまうため、スケールアップが効果的であるという考えです。
次は、メモリ使用率が高いケースについて考えていきます。
メモリ使用率が高いケース
メモリ使用率が高い場合は以下の対応が基本となります。
アクセス数が増えて高負荷になっている場合:スケールアウト
メモリ使用量が多い処理が多くて捌き切れない:スケールアップ
メモリ断片化でメモリ使用率が上がり続ける:新しいデプロイの強制
アクセス数が増えて高負荷になっている場合、タスク数を増やすことで、多くのアクセスを捌けるようになるため、スケールアウトすれば良いという考えです。
メモリ使用量が多い処理が多くて捌き切れない場合、タスク数を増やしても、重い処理が1つのタスクに集中してしまうと捌けなくなってしまうため、スケールアップが効果的であるという考えです。
メモリ断片化でメモリ使用率が上がり続ける場合、タスクの入れ替えをすれば、メモリ断片化されていないタスクのみに切り替わるため、新しいデプロイの強制が有効と考えています。
どのような対策をすべきかわかったところで、具体的に
・スケールアウト
・スケールアップ
・新しいデプロイの強制
の実施方法について記載していきます。
スケールアウト・スケールアップ・新しいデプロイの強制を実施する方法
具体的な手順について記載していきます。
まずはスケールアウトから
スケールアウト
AWSマネージメントコンソールのECS画面から、サービスの編集画面を開き、「必要なタスク」を増やして更新します。
「必要なタスク」は以下の画面の赤線の場所から編集できます!
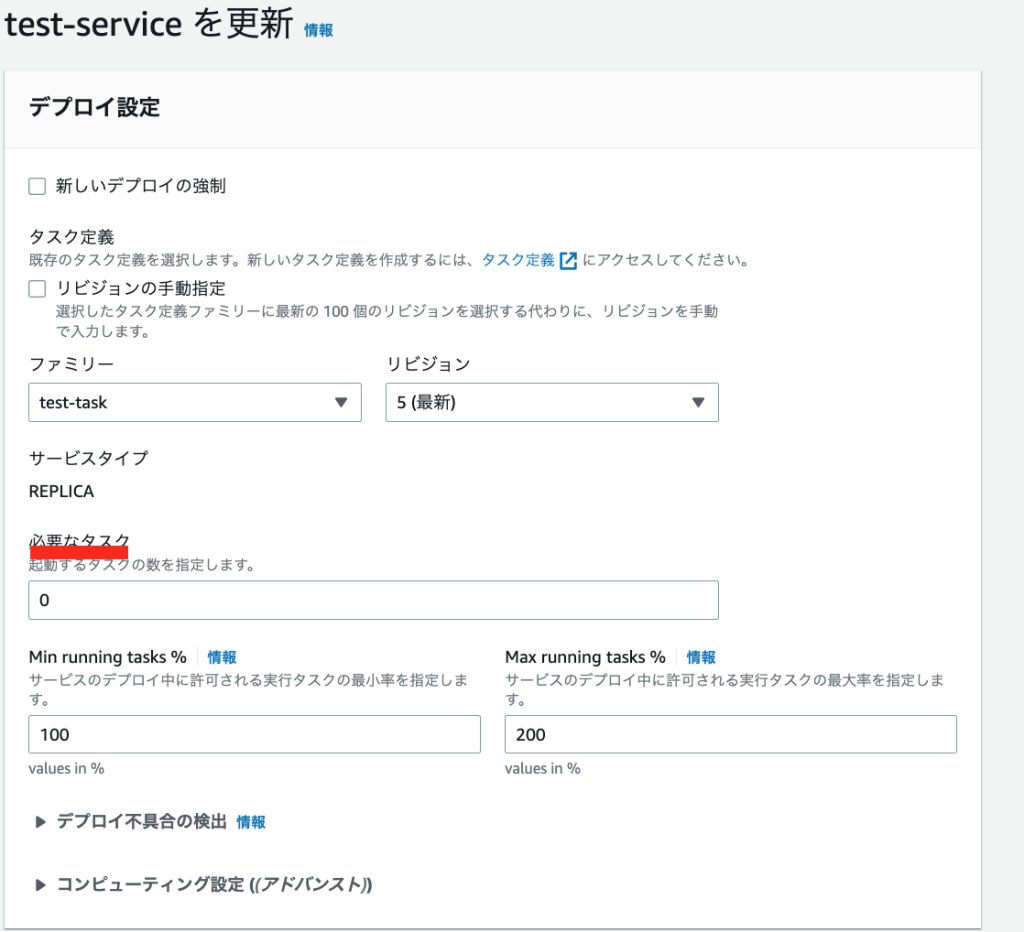
ECS タスク数を増やして、スケールアウトする
上記のように、手動でタスク数を変更することも可能ですが、オートスケーリングを設定しておくのがスマートかと思います。
オートスケーリングの設定は以下の記事をご参照ください。

スケールアップ
タスク定義からCPU・メモリの性能を更新し、サービスの「新しいデプロイの強制」をONにして更新します。
「CPU」「メモリ」の性能は以下の画面の赤線の場所から編集できます!
新しいデプロイの強制はこちらをご参照ください。
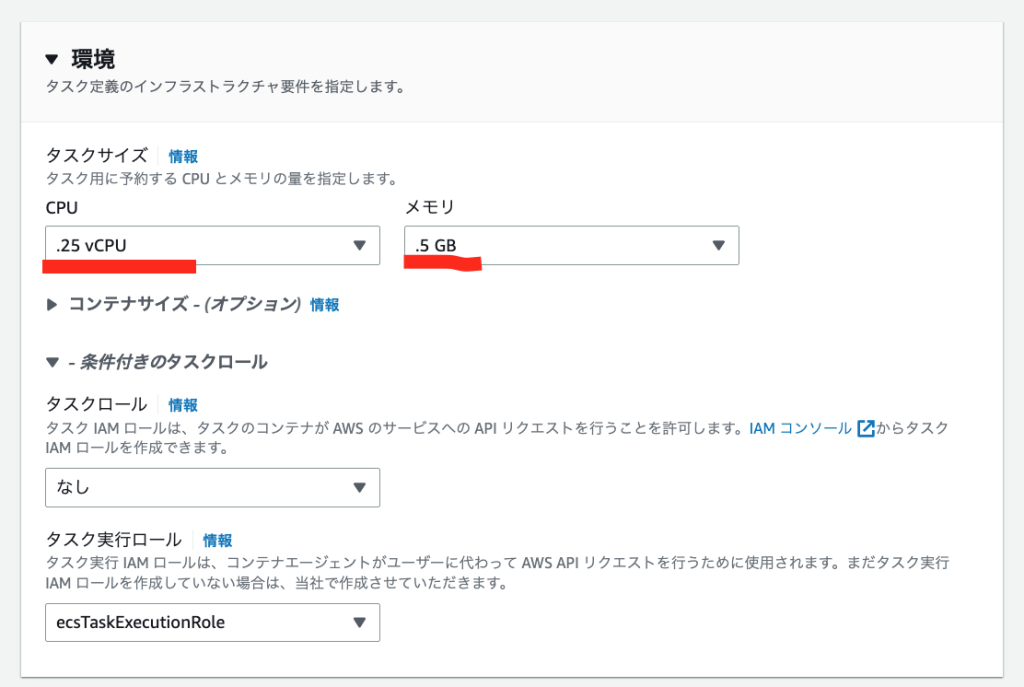
ECS タスクの性能を修正して、スケールアップする
新しいデプロイの強制
サービスの編集画面を開き、「新しいデプロイの強制」のONにして更新します。
「新しいデプロイの強制」は以下の画面の赤線の場所から編集できます!
ONにして更新すると、タスクの入れ替えが行われます。
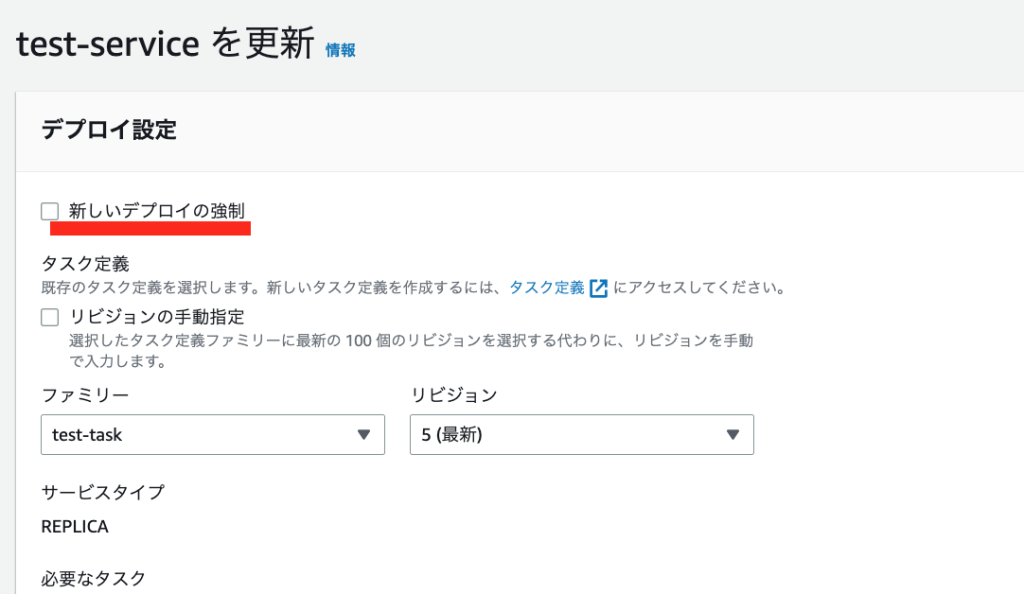
新しいデプロイの強制
「新しいデプロイの強制」は、新しいコンテナを起動し、稼働中のコンテナを停止する挙動になりますが、停止するコンテナの挙動は以下の通りとなります。
更新中にサービススケジューラがタスクを置き換えるとき、サービスはまずロードバランサーからタスクを削除し (使用されている場合)、接続のドレインが完了するのを待ちます。その後、タスクで実行されているコンテナに docker stop と同等のコマンドが発行されます。この結果、
SIGTERM信号と 30 秒のタイムアウトが発生し、その後にSIGKILLが送信され、コンテナが強制的に停止されます。コンテナがSIGTERM信号を正常に処理し、その受信時から 30 秒以内に終了する場合、SIGKILL信号は送信されません。

コンテナは30秒の猶予時間の間に、正常に処理を終わらせられるように動く。
まとめ
以下の負荷のケースと対策について記載しました。
CPU使用率が高いケース
対策:アクセス数が増えて高負荷になっている場合:スケールアウト
対策:重い処理が多くて捌き切れない:スケールアップ
メモリ使用率が高いケース
対策:アクセス数が増えて高負荷になっている場合:スケールアウト
対策:メモリ使用量が多い処理が多くて捌き切れない:スケールアップ
対策:メモリ断片化でメモリ使用率が上がり続ける:新しいデプロイの強制
スケールアップ・スケールアウト・新しいデプロイの強制を適切に使って乗り越えていきましょー
